Lane2Seq: Towards Unified Lane Detection via
Sequence Generation(CVPR 2024)
Kunyang Zhou
Southeast University
kunyangzhou@seu.edu.cn
[Paper]
[Github(Coming soon)]
[BibTeX]
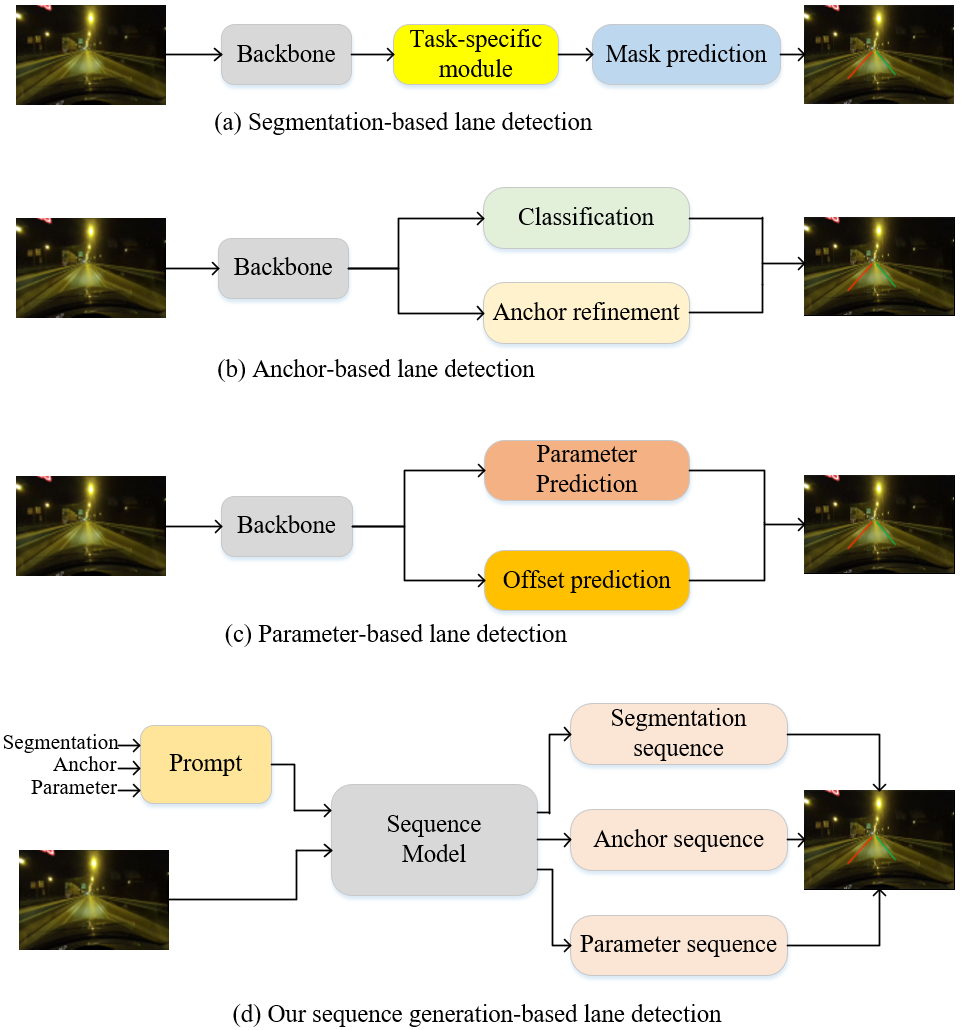
In this paper, we present a novel sequence generation-based framework for lane detection, called Lane2Seq. It unifies various lane detection formats by casting lane detection as a sequence generation task.
This is different from previous lane detection methods, which depend on well-designed task-specific head networks and corresponding loss functions. Lane2Seq only adopts a plain transformer-based encoder-decoder architecture with a simple cross-entropy loss.
Additionally, we propose a new multi-format model tuning based on reinforcement learning to incorporate the task-specific knowledge into Lane2Seq. Experimental results demonstrate that such a simple sequence generation paradigm not only unifies lane detection but also achieves competitive performance on benchmarks.
For example, Lane2Seq gets 97.95% and 97.42% F1 score on Tusimple and LLAMAS datasets, establishing a new state-of-the-art result for two benchmarks.
Methodology
In this paper, we present a novel sequence generation-based lane detecton (Lane2Seq) framework to tackle the aforementioned issues. By formulating the lane detection as a sequence generation task, Lane2Seq gets rid of customized head networks and task-specific loss function.
It is based on the intuition that if the detection model knows where the target lane is, model can be simply teached how to read the location of lane out, instead of designing additional classification head or regression head by the divide-and-conquer strategy.
While Lane2Seq does not contain task-specific components, task-specific knowledge contained in these components can help the model learn the features of lanes better. We propose a Multi-Format model tuning method based on Reinforcement Learning (MFRL) to incorporate the task-specific knowledge into the model without changing model's architecture. Inspired by Task-Reward, MFRL takes the evaluation metrics,
which naturally integrates task-specific knowledge, as the reward and tunes Lane2Seq using REINFORCE algorithm. However, evaluation metrics like F1 score cannot be used as the reward directly due to undecomposable as a sum of per-example rewards. In this paper, we propose three new evaluation metric-based rewards for segmentation, anchor, and parameter format, based on their task-specific knowledge.

Results and Comparisons

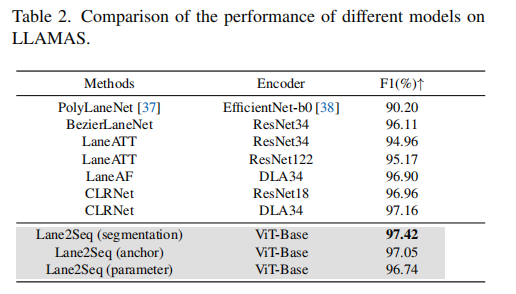
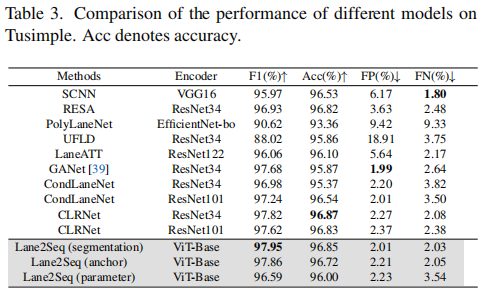
Based on the above results, we can conclude that the unified lane detection via the sequence generation without any well-designed task-specific components, combining our reinforcement learning-based multi-format model tuning, can achieve promising performance.
About me
I am a second-year (2022-now) M.S. student in School of Automation, Southeast University.
Open source contribution
I've been working to open source meaningful projects for the PaddlePaddle community. So far, I've gotten 5.5K forks in the PaddlePaddle community and am a top 100 contributing developer!
My homepage in the PaddlePaddle community is here.
Acknowledgment
I would like to express my sincere thank to my girlfriend very much for her support and encouragement throughout this project. Her companionship gave me the strength I needed to complete this project.
Project page template is borrowed from simplehand.